This repository contains data and information regarding for the paper
M. Trevisan, D. Giordano, I. Drago, M. Mellia, M. Munafò, “Five Years at the Edge: Watching Internet From the ISP Network,” in IEEE/ACM Transactions on Networking, vol. 28, no. 2, pp. 561-574, April 2020, doi: 10.1109/TNET.2020.2967588.
A preliminary version of the paper appeared as M. Trevisan, D. Giordano, I. Drago, M. Mellia, M. Munafò, Five Years at the Edge: Watching Internet from the ISP Network, ACM CoNEXT 2018, Heraklion, Crete.
We provide an in-depth longitudinal view of Internet traffic taking a point of the view of a national-wide ISP. We analyze 5 years of flow- level rich measurements – or about 250 billion traffic records. We evaluate the providers’ costs in terms of traffic consumption imposed by users and services. We show that an ordinary broadband subscriber nowadays downloads more than twice as much as they used to do 5 years ago. Bandwidth hungry video services drive this change, while social messaging applications boom (and vanish) at incredible pace. We study how protocols and service infrastructures evolve over time, highlighting unpredictable events that may hamper traffic management policies. In the rush to bring servers closer and closer to users, we witness the birth of the sub-millisecond Internet, with caches located directly at ISP edge frontier.
Open dataset (New)
Our dataset is open to anyone interested in reproducing our results or performing further analysis.
The samples above are composed of multiple tar.gz files containing csv files. Each tarball contains a snapshot for a month and an access technology. TCP and UDP logs are provided in separated files. Files contain a subset of the columns exported by tstat (see format here).
As explained in the paper, client IP addresses and server names are the most privacy-sensitive information in the data. Client IP addresses get immediately anonymized by the collection probes. In the public dataset linked above, also server IP addresses are anonymized. To keep information about traffic destinations, the AS numbers associated with the server IP addresses are obtained before anonymization (using CAIDA’s pfx2as).
Host names are also anonymized in the public dataset. However, each flow is annotated with with the service behind the flow using the regular expressions that can be found below. All flows not belonging this list of popular services are marked as “others”.
Full dataset
The full dataset contains all columns exported by tstat in different vantage points since 2013, including some vantage points not discussed in the paper. The repository presently amounts to around 70 TB of compressed logs.
Researchers interested in accessing the dataset must:
- Contact the authors, by sending an email stating the purpose of the research, the people/companies involved and how the traces could help its development
- Sign a non-disclosure agreement (NDI). The agreement states, among other things, that no data (in any format) can leave our premises. For example, collaborators cannot publish further data without explicit consent of the data owners
We are always happy to collaborate with other researchers interested in exploring new aspects of these traces, and in fact requests to use the datasets have usually resulted in fruitful research collaborations. Some results from such collaborations can be found here, here, here and here.
Since logs cannot leave our premises, they must be processed on Polito’s computing facilities.
Explorable data
We provide below high-level and aggregated summaries of the traces.
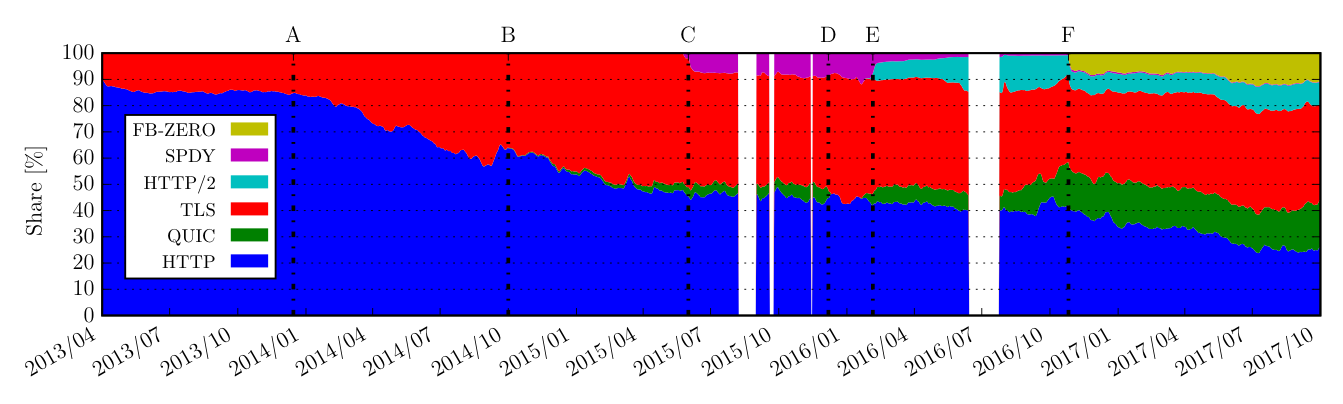
B – Google starts deploying QUIC in the wild
C – Time for SPDY
D – Google disables QUIC for security issues
E – the born of HTTP/2
F – Now Facebook comes out with its own transport protocol – FB-ZERO
The service classification rules
Below you can find the regular expressions we used to extracted the service from the raw data. We details the list of regex for each service.
Audio spotify: "\.spotify\.com$", "\.scdn\.co$", "\.scdn\.com$" deezer: "\.deezer\.com$", "\.dzcdn\." Video youtube: "\.googlevideo\.com$", "\.ytimg\.com$", "\.youtube\.com$", "\.gvt1\.com$", "\.youtube-nocookie\.com$" netflix: "\.netflix\.", "\.nflxext\.", "\.nflximg\.", "\.nflxvideo\.", "\.nflxso\." vimeo: "vimeo\.com$", "\.vimeocdn\.com$", "vimeopro\.com$" adult: "porn", "\.ypncdn\.", "\.phncdn\.", "\.xvideos\.", "\.megasesso\.", "\.xnxx\.", "\.livejasmin\.", "\.xhamster\.", "imlive\.com$", "\.youjizz\.com$", "\.hclips\.com$", "culonudo", "tnaflix\.com$" rai: "\.rai\.it$", "\.raiplay\.it$", "\.raiplayradio\.it$", "\.raitalia\.it$", "everyrai-", "[0-9]sspushrai[0-9]-", "$rai*.akamaihd\.net$" mediaset: "\.mediaset\.it$", "\.mediasetpremium\.it$", "\.mediaset\.net$", "msp\.ticdn\.it$", "^rtinfinity", "msf\.ticdn\.it" sky: "\.sky\.it$", "\.sky\.com$", "skylivehssctv\.cdn\.fastweb\.it", "sky\.ticdn\.it", "skyvodabr\.cdn\.fastweb\.it", "skylivehssctv\.cdn\.fastweb.it$" Social facebook: "\.facebook\.com$", "\.fbcdn\.net$", "\.facebook\.net$", \ "^fbcdn", "^fbstatic", "^fbexternal", "\.fbsbx\.com$" twitter: "\.twitter\.", "\.twimg\.", "^twitter\.com$", "twitter\.com\.edgesuite\.net", "twitter-any\.s3\.amazonaws\.com", "twitter-blog\.s3\.amazonaws.com" linkedin: "\.linkedin\.com$", "\.licdn\.com$", "\.lnkd\.in$" instagram: "\.instagram\.com$", "\.cdninstagram\.com$", "^igcdn" Search engine google: "^www\.google\.it$" bing: "\.bing\.com$" yahoo: "\.yahoo\.com$", "\.yahoo\.net$", "\.yimg\.com$" duckduck: "\.duckduckgo\." Ecommerce ebay: "\.ebay\.", "\.ebaystatic\.com$", "\.ebayimg\.com$", "\.ebayrtm\.com$", "\.ebaydesc\.com$", "\.ebayinc\.com$" amazon: "\.amazon\.it", "\.fls-eu.amazon\.", "\.images-amazon\.com$", "images-eu\.amazon\.com$" alibaba: "\.alibaba\.com$", "\.alicdn\.com$", "\.taobao\.com$" Chat whatsapp: "\.whatsapp\.com$", "\.whatsapp\.net$" telegram: "\.telegram\.org$", "^telegram\.org$" viber: "\.viber\.", "^viber\.kayako\.com$" snapchat: "\.snapchat\.com$", "feelinsonice\.appspot\.com$", "feelinsonice-hrd\.appspot\.com$", "feelinsonice\.l\.google\.com$" skype: "\.skypeassets\.com$", "\.skype\.com$", "\.skype\.net$"