User Account
To access the BigData@Polito Cluster you need a user account. Request the credentials.
For support, accounts or technical issues, write to supporto@smartdata.polito.it.
Jupyter Interface – Spawning a Server
The primary interface for the cluster is via JupyterLab: https://jupyter.polito.it/
After login, spawn a server among the images at your disposition.
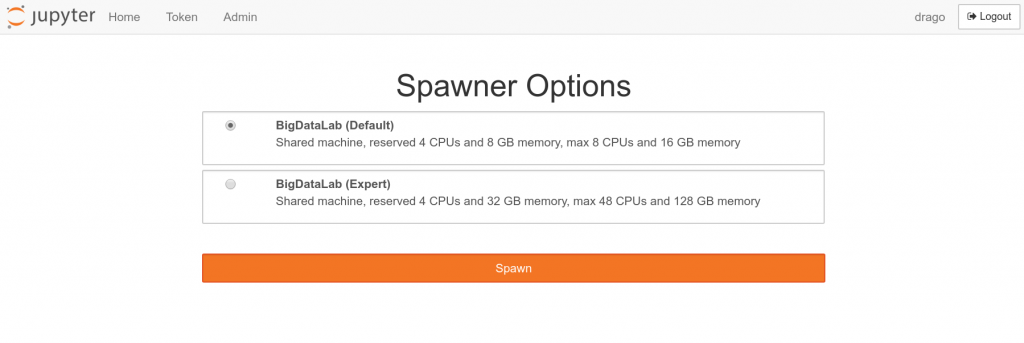
Coming soon: With the new BigData Cluster, more powerful images will become available for all users. More powerful images will have a limited lifetime (i.e., the biggest images will be culled everyday). Less powerful images can be used for longer interval instead (e.g., up to a week).
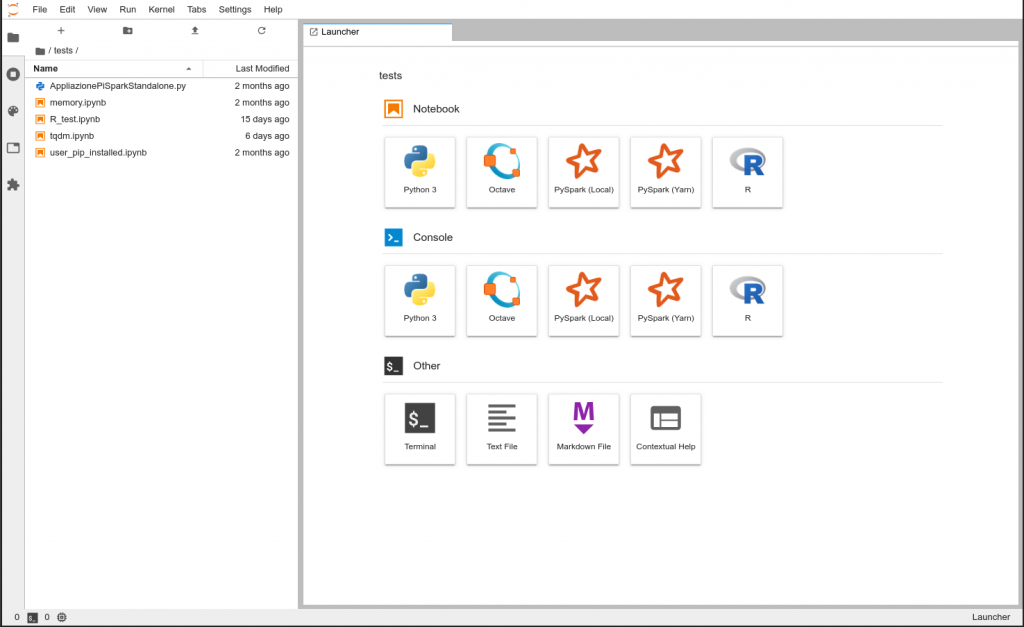
Jupyter Interface – Main Interface
In the main jupyter interface you can start PySpark notebooks, running your master in the notebook server (local) or in the big data cluster (yarn). You can open your terminal or interact with your home folder in the left panel. Other notebooks are also available, such as R and Octave.
Accessing BigData@Polito Hadoop Services
<< The preferable interface to interact with the cluster is the JupyterHub listed above >>
You can also access the cluster via the Access Gateway bigdatalab.polito.it. Connecting to
$ ssh your_username@bigdatalab.polito.it
You can interact with the HDFS file system, copy your data to/from the cluster, and submit your jobs. You can find here a list of available commands. Note that limited resources are available in the gateway and strict quotas are enforced. If you need to perform heavy analysis in the gateway, fire a large image via JupyterHub.
Web Interfaces to the Hadoop Services
For more flexible access to the system, you can use one of the web interfaces for the services. The preferred means to interact with the services is via the Hue service: https://bigdatalab.polito.it/

Again, use your credentials for signing in, then you can interact with the services (e.g., HDFS).
Advanced Use Cases
| HDFS | https://ma1-bigdata.polito.it:9871/https://mb1-bigdata.polito.it:9871/ |
| YARN Job History | https://ma1-bigdata.polito.it:19890/jobhistory/ |
| YARN Resource Manager | https://ma1-bigdata.polito.it:8090/cluster/ |
For accessing the YARN Job History, the YARN Resource Manager and the HDFS web interfaces, you will need to get a kerberos ticket in your PC and your browser must support HTTP SPNEGO, as described below.
Security Information
HTTPS and TLS connections to the private BigData@Polito servers (available only from Polito network) are signed by our BigData Lab Root CA. You can either add in your browsers security exceptions to all the servers involved, or you can decide to trust the BigData Lab Root CA installing, in order, its certificates on your system.
Using your own Hadoop Clients
For complex development or special needs, e.g. large local disk space, we suggest you to deploy your own local Hadoop system and configure to act as a client for the BigData@Polito cluster.
The software currently used in on BigData@Polito is the Cloudera CDH distribution. Consult the installation requirements and instructions for any information: you will need to perform an “unmanaged deployment” using the provided packages. If the current Cloudera version is more recent than the one on the cluster, follow the instructions about “Installing an Earlier Release”.
You still need valid BigData@Polito credentials, the correct Kerberos configuration, and you must verify that AES-256 Encryption is enabled for your Java JDK. More information here.
After installing the software, you need to configure it to interact the BigData@Polito cluster, downloading the following Client Configuration files, and deploying them in the respective configuration directories:
- HDFS Client Configuration
- YARN Client Configuration
- HBase Client Configuration
- Hive Client Configuration
Please notice that we cannot help you directly with the deployment of your personal Hadoop system, beside giving you the general information about the required software versions and providing you the Client configuration files: for any other problem you must contact your IT support.
Kerberos Client Configuration
Edit your Kerberos client configuration file, usually located in /etc/krb5.conf, to add the BigData@Polito servers:
[libdefaults]
default_realm = BIGDATA.POLITO.IT
[realms]
BIGDATA.POLITO.IT = {
kdc = ma1-bigdata.polito.it
kdc = mb1-bigdata.polito.it
admin_server = ma1-bigdata.polito.it
}
Verify you can obtain your Kerberos ticket issuing the command
$ kinit <your_username>
If the system is correctly configured you will receive no error message. You can verify the status of your ticket with the command
$ klist
If you cannot obtain the ticket, check that the Kerberos KDCs can be reached from your terminal, or contact your IT support.
Web Browser Configuration
To use the Web Interfaces for the BigData Hadoop Services you must configure your browser to utilize the Simple and Protected GSS-API Negotiation (SPNEGO) mechanism.
HTTP SPNEGO is enabled by default on Safari and Google Chrome. Instructions on how to enable SPNEGO in Firefox and other browsers are available at the links below. The HTTP SPNEGO whitelist must include the “.polito.it” domain.