User Account
To access the BigData@Polito Cluster you need a user account. Request the credentials.
For support, accounts or technical issues, write to supporto@smartdata.polito.it.
Jupyter Interface – Spawning a Server
The primary interface for the cluster is via JupyterLab: https://jupyter.polito.it/
After login, spawn a server among the images at your disposition.
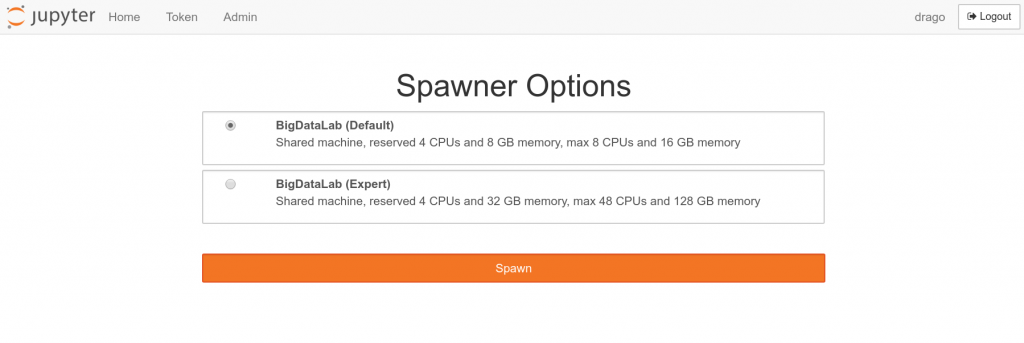
Coming soon: With the new BigData Cluster, more powerful images will become available for all users. More powerful images will have a limited lifetime (i.e., the biggest images will be culled everyday). Less powerful images can be used for longer interval instead (e.g., up to a week).
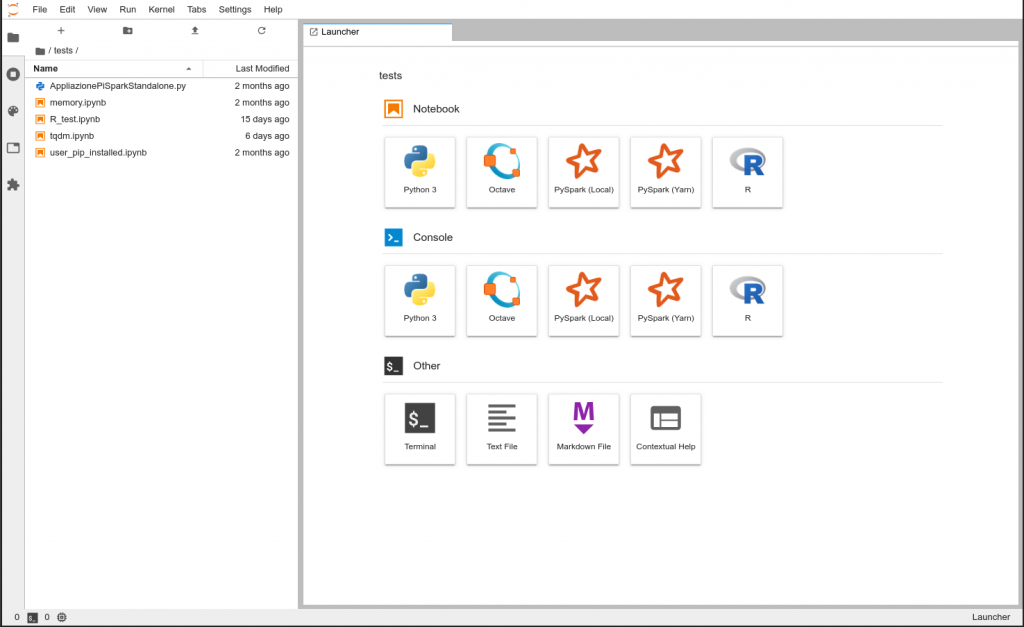
Jupyter Interface – Main Interface
In the main jupyter interface you can start PySpark notebooks, running your master in the notebook server (local) or in the big data cluster (yarn). You can open your terminal or interact with your home folder in the left panel. Other notebooks are also available, such as R and Octave.
How to Change Your Password (Step by Step Guide)
Changing your password is simple and fundamental to secure your account.
Make sure your new password is strong (at least 8–12 characters, with a mix of letters, numbers, and symbols).
Below you find the complete guide you can follow.
Step 1: Open a Terminal
First, you need to open your terminal.
– You can open the terminal from the “Launcher” tab.
Step 2: Run the passwd Command
Once the terminal is open, type the following command and press Enter:
passwdStep 3: Enter Your Current Password
The system will first ask for your current password. Type it in and press Enter.
(Note: when typing your password, nothing will appear on screen — this is normal for security reasons.)
$ passwd
Current password: ********Step 4: Enter a New Password
Next, you will be prompted to enter your new password:
New password: ********Step 5: Confirm Your New Password
You will be asked to type your new password again for confirmation:
Retype new password: ********Step 6: Success Message
If everything matches, you will see a message similar to this:
passwd: password updated successfullyCongratulations! You’ve successfully changed your password.
Example of the Full Process
Here’s what it looks like in a real terminal session:
$ passwd
Changing password for user john
Current password: ********
New password: ********
Retype new password: ********
passwd: password updated successfully