Summary
Here you can find scripts and datasets of anonymized clickstreams presented in the following papers:
- Vassio, L., Drago, I., Mellia, M., Ben-Houidi, Z., and Lamali, M.L.. (2018) You, the Web and Your Device: Longitudinal Characterization of Browsing Habits. ACM Transactions on the Web 12, 4, Article 24 (September 2018), 30 pages. DOI: https://doi.org/10.1145/3231466
- Vassio, L., Drago, I., and Mellia, M. (2016) Detecting User Actions from HTTP Traces: Toward an Automatic Approach. (link is external)In: Proceedings of the 7th International Workshop on Traffic Analysis and Characterization (TRAC). Paphos, Cyprus. pp. 50-55. DOI 10.1109/IWCMC.2016.7577032.
This page may be updated to accommodate new analyses.
Clickstreams: anonymized dataset
We build clickstream graphs given the requested pages and the hyperlinks followed by people in a household while navigating using each specific browser-app. In total, we have 5.5 million graphs corresponding to over 1 billion visited pages from June 2013 to June 2016., which we make available to the community in anonymized form for further investigation.
The shared folder (link is external) contains archives for each month and for each of the three PoPs for 3 years. Each file has a name <PoP>_<yyyymm>.txt.gz where <PoP> is the PoP identifier, <yyyymm> indicates the year (2013, 2014, 2015 or 2016) and the month (1 to 12). Inside each file there are the clickstreams of browser-apps: a new browser app is identified by a line containing only the string clickstream. Following this line, a new line describe the browser-app type. The order of browser apps is randomly chosen each month. Then, the lines until a new clickstream (or end of file) are odered chronologcally and contains the following information:
<timestamp> <fromDomain>/<fromUrl> <toDomain>/<toUrl>
<timestamp> is Unix time in seconds, with granularity up to 1/100 of seconds. <fromDomain> and <toDomain> are integer codes corresponding to a unique domain. The same code corresponds to same domain in all the dataset. <fromUrl> and <toUrl> are integer codes corresponding to unique url. This code is univoque just for a single clickstream of a browser-app for a month. If there is no referer <fromDomain>/<fromUrl> is equal to “-“.
User-action classifier: training data
The clickstreams are extracted from HTTP logs passively collected in the network using Tstat. A key challenge to build the clickstreams is to identify which records in the logs represent HTTP requests explicitly fired by a user-action, and which ones are automatic HTTP requests fired by browsers and mobile-apps to render web pages. We have developed a system to identify user-actions in HTTP logs based on machine learning.
The model is built using decision trees and trained data collected from volunteers. The following archive contains features extracted from volunteers’ data and an example of model built with Weka (link is external) using random forests. Each line in the datasets contains features describing a HTTP request and is annotated with a label indicating whether the HTTP request is a user-action or not.
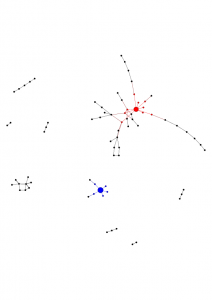
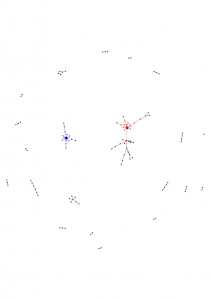
Examples of clickstreams
Examples of extracted clickstream graphs. Google and its neighbors are in red, Facebook and its neighbors in blue.
| Graph N.1 | Graph N.2 | Graph N.3 |
 |
 |
 |
Example of the performed analyses
An abstract that illustrates the type of analysis we have performed with this dataset:
Understanding how people interact with the web is key for a variety of applications — e.g., from the design of effective web pages to the definition of successful online marketing campaigns. User browsing behavior has been traditionally represented and studied by means of clickstreams — i.e., graphs whose vertices are pages and edges are the paths followed by users. Obtaining large and representative data to extract clickstreams is however challenging. The evolution of the web questions whether user behavior is changing and, by consequence, whether properties of clickstreams are changing. This paper presents a longitudinal study of clickstreams in the last 3 years. We capture an anonymized dataset of HTTP traces in a large ISP, where thousands of households are connected. We first propose a methodology to identify actual URLs requested by users from the massive set of requests automatically fired by browsers when rendering pages. Then, we characterize web usage patterns and clickstreams, taking into account both the temporal evolution and the impact of device used to explore the web. Our analyses uncover and quantify interesting patterns, such as the increasing trend on the usage of mobile devices to explore the web, the limited number of pages typically visited by users while at home, and the higher importance of social networks for content promotion in smartphones when compared to PCs.